The Weed Manager’s Guide To Remote Detection
The Weed Manager’s Guide To Remote Detection
- Home
- About us
- Detecting weeds
- Get involved
- Resources
The development of a model for weed detection can adopt the general model development pipeline illustrated in the figures below.
A common AI project has the following participants, who are responsible for certain components of the development:
Since the key ingredient to successful AI models is data, the focus is on producing quality data (Geiger et al., 2021; Maxwell et al., 2021; Jordan, 2018, 2019).
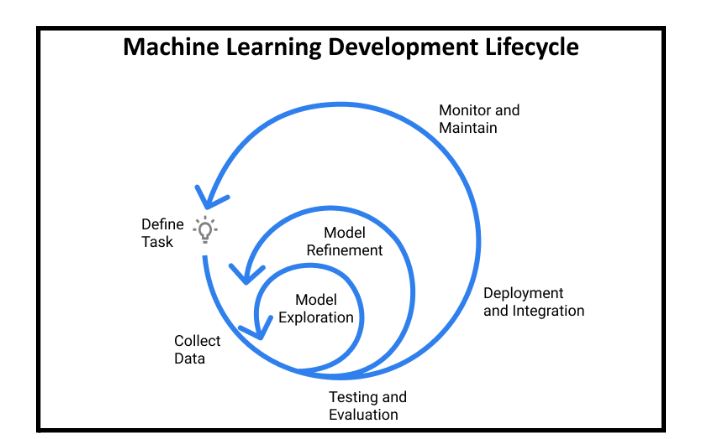
Figure 1 illustrates the complexity of a machine learning model and its key components, while figure 2 shows the development lifecycle and its iterative returns to earlier stages.
Fig.1. The components of a machine learning model (https://www.neuraxio.com/blogs/news/the-business-process-of-machine-learning-with-automl)
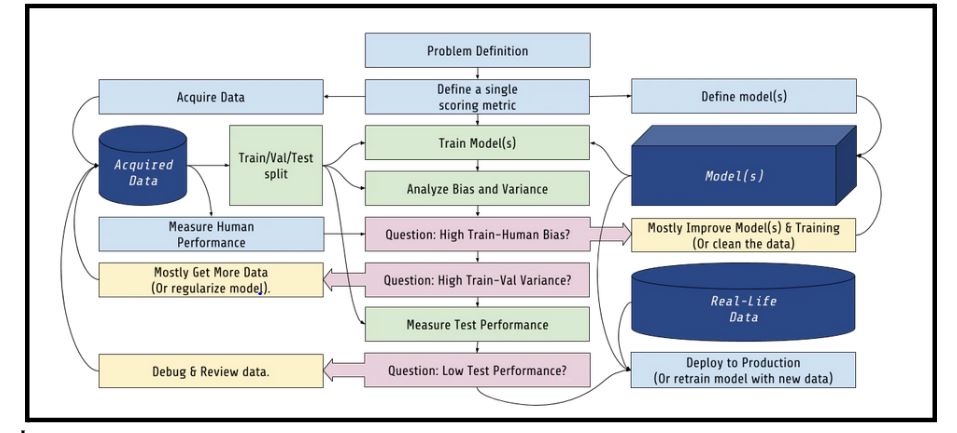
Fig.2. The Machine Learning Development Lifecycle (https://www.jeremyjordan.me/ml-projects-guide/)
The key question that can be taken from the business process of developing AI applications also applies to the research case: what is the end-user requirement?
This will drive many factors of the development lifecycle and also inherently the treatment of data. End-users will most likely treat the developed models as black-boxes, without wanting to be required to know too much about intricate workings such as labelling additional images. The end user requirements drive the definition of data, desired behaviour and associated software.
Supervised Deep Learning requires datasets to train and evaluate the performance of a model. Supervised learning requires labelled data, where a human provides the “True” output that the model should learn (see section on “labelling”).
In general, datasets are split into three parts:
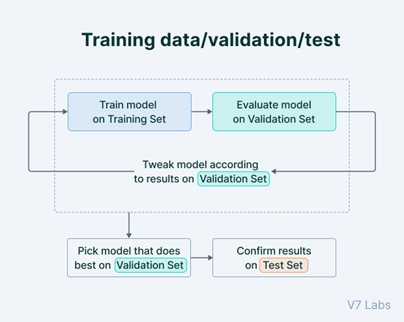
Fig. 1. Process for using training, validation and test datasets in AI model development (Train Test Validation Split: How To & Best Practices [2023] (v7labs.com))
The test dataset is generally withheld from the model at training and it is essential that this dataset resembles the real-world scenario the closest - it is the “real-world” dataset. It is also essential that the test dataset is never mixed into the training dataset. Both datasets should always be separate and the test dataset should also be kept constant over time, to be able to compare models when improving them.
Training and validation dataset usually come from the same bulk and are split at model training time. The parameters of the model are updated using samples from the training dataset, while the accuracy is evaluated on the validation dataset. When the performance no longer improves on the validation dataset, the model parameters are stored and the performance is tested on the test dataset (or the real world dataset) for the final reporting value.
The data formats developed by the end-user drive the supplementary software developments. If georeferenced files such as geotiffs are the desired input, the pipeline will have to look different than for standard images that are generated by smartphones. Image stitching artifacts and resolution differences, as well as data loading pipelines are inherently common in these cases and differ from standard CV data formats (Huang et al., 2019).
Additionally, the question if it is more important to detect every specimen, at the expense of False Positives, or detect only reliable specimen, at the expense of False Negatives, can drive model hyperparameters such as the choice of a loss function (Maxwell et al., 2021).
At the outset of any model development, a list of questions to discuss with the project team will be helpful to ensure that the species is fully understood by the team so as to best enable accurate identification of the target species in the images for labelling purposes. Early information regarding the data and AI techniques that may be most appropriate to employ for model development is also necessary at the beginning of the process.
The project team should document discussions around the following questions:
These issues require clarification before the model development can begin, as these drive the development of models and are early indicators of success.
Another question that requires definition is the deployment strategy and available hardware resources. Models have become ever more resource intensive and require large GPUs, even more so during training. Development of models requires access to GPUs and how these are hosted defines the libraries and tools available for the development of models, e.g. data handling, libraries, training settings, etc. Commercial tools such as azure, AWS or roboflow allow easy use for off-the-shelf tasks, however, they are less flexible in the definition of model parameters and settings, peculiar to non-standardised data. Commercial tools for deep learning such as azure, AWS or roboflow facilitate use by removing some technical difficulties, however, they are less flexible in the definition, operation and technical literacy to use, features which are not necessarily given for end -users as much as developers.
Python is by far the most popular language for AI model development. It is a general-purpose language that is easy to learn and use, and it has a large library of libraries and tools that are specifically designed for AI. Some of the most common Python AI libraries, such as TensorFlow, PyTorch and Scikit-learn are also compatible with other popular programming languages, such as R, Java, and C++. However, as the use of these libraries requires programming skills, the development of AI models using them typically requires the involvement of a specialised data scientist.
Given the widespread adoption of AI models, cloud computing providers such as AWS, Azure or Roboflow offer managed AI services. These services provide a turnkey solution for developing and deploying AI models. They typically include pre-trained models, pre-built pipelines, and managed infrastructure. This can make it much easier for scientists to get started with AI without having to invest in the infrastructure or expertise required to build and manage their own models. These tools provide a graphical user interface (GUI) for building and training AI models. This can make it easier for businesses to develop AI models without having to learn how to code. One limitation of these solutions is that they can make it difficult to understand how AI models work. This is because they abstract away from the underlying complexity of the process, making it difficult to see how the models make decisions. This can make it difficult to identify and address potential biases or errors in the models. As with any model it is critical to test the models thoroughly before deploying them into the field so that you can be sure they work as expected and that they do not exhibit any bias or errors
Examples of specific pipelines for RGB, MS and HS imagery are shown below (taken from the recent research project :”Weed Managers Guide to Remote Detection”:
Fig.1. imagery processing and analysis pipeline for RGB imagery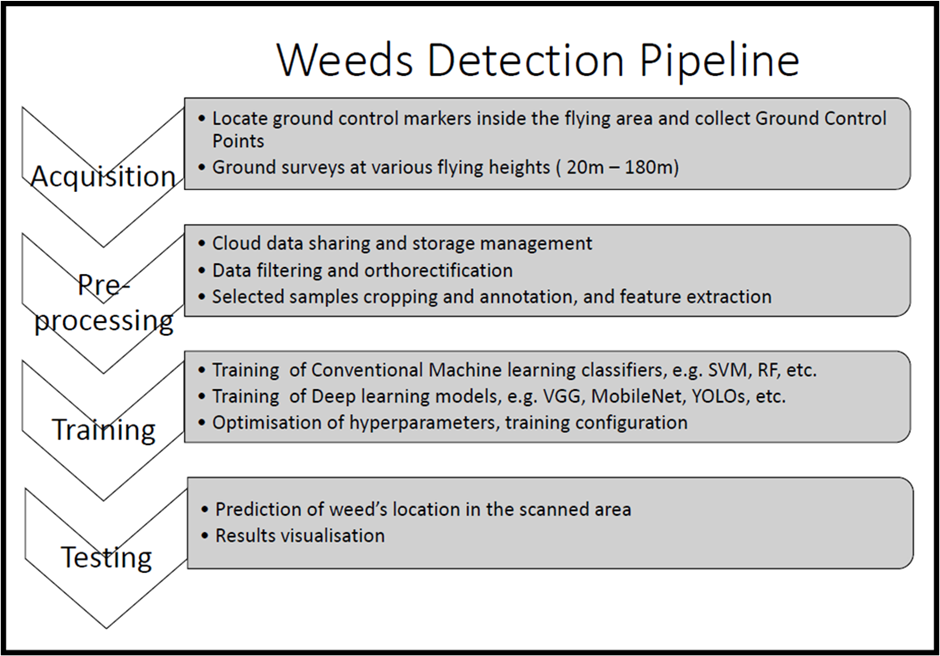
Source: Dr. M. Rahaman, Charles Sturt University
Fig. 2. imagery processing and analysis pipeline for HS/MS imagery
Source: N. Amarasingam, Queensland University of Technology